See the technology in action.
The best way to understand how hybrid models work is to see them solving your team's actual problems.
Our platforms are built on hybrid models — combining AI, physics, chemistry, and omics into a single architecture. Plus a growing library of digital twins for the food processes that matter most.

Most AI-for-food platforms are pure machine learning — they can only predict what they've seen before. Most simulation platforms are pure physics — they can't learn from data. PIPA combines four modeling approaches into a single prediction. That's why our systems work where either alone falls short.
Pattern recognition across tens of millions of recipes, scientific papers, and production runs. Knowledge graphs connect compounds to mechanisms to outcomes. Learns patterns no human analyst can hold in their head at once.
First-principles simulation of food processes — heat transfer, mass transfer, phase change, rheology, and chemical reaction, all solved simultaneously. This is where off-the-shelf CAE tools fail and where we shine.
Reaction kinetics, degradation pathways, ingredient interactions. Plus omics-level data — metabolomics, proteomics, transcriptomics. The chemistry a formulation will actually do, modeled alongside the data on how ingredients behave in the body.
Every model continuously improves against real manufacturing runs. Predictions get better with each batch. Customer data stays in customer systems, but the models learn the shape of food processes from what's observed in production.
A decade of peer-reviewed science.
PIPA authors have contributed 50+ peer-reviewed publications in leading food and health journals, alongside issued patent coverage on our core AI methodology. Every platform capability traces back to work that has passed scientific peer review.
Connected to the frontier of food-systems research.
Active research collaborations with leading academic institutions including the AI Institute for Next Generation Food Systems (AIFS), the Innovation Institute for Food and Health (IIFH), and the University of California, Davis. Fundamental research informs our platforms; commercial deployments inform research priorities.
Ten years of codebase and domain expertise.
A mature, production-hardened code base powering FIOS and LEAP, built on proprietary solutions across AI/ML, knowledge graphs, multiphysics, and chemoinformatics. Combined with deep domain expertise across food science, nutrition, and bioinformatics.
Pure ML models tell you what's likely — but they can't tell you why, and they break on novel formulations. Pure physics models tell you why — but they're slow, brittle, and need exact material properties nobody has. Hybrid models combine both: the speed and breadth of ML, grounded in the physical and chemical reality that physics enforces.
The practical result: FIOS can predict how a product will scale up before you've made it, and explain why. LEAP can suggest a novel bioactive and show the mechanistic pathway from ingredient to outcome. That's not what pure ML does. That's not what pure simulation does. It's what hybrid models make possible.
Off-the-shelf CAE tools don't handle food processes well — too much coupled physics, too much chemistry, too many phase changes. So we build digital twins from first principles, calibrate them to real production data, and extend the library as customers need new processes modeled.
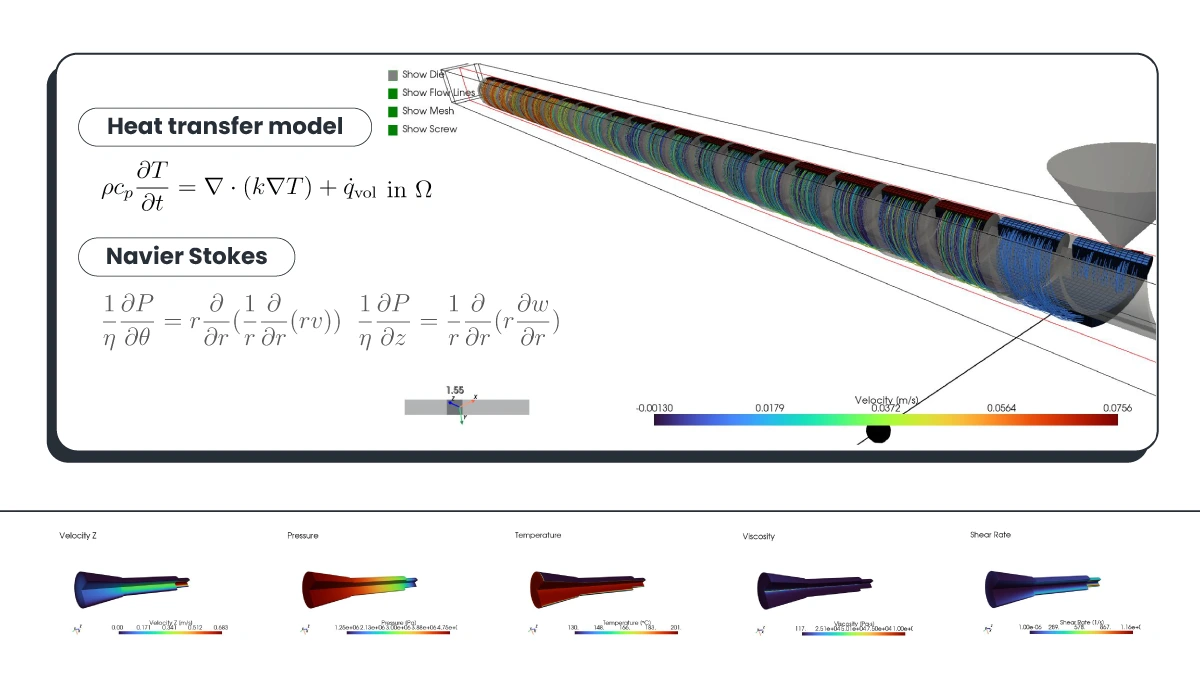
Predicts texture, expansion, and density. Optimizes screw configuration and thermal zones before committing to a run.
A subset of the coupled physics: heat transfer between material and barrel, Navier-Stokes flow through screw channels and die, viscosity and shear resolved in a virtual environment and continuously refined through multivariate process monitoring.
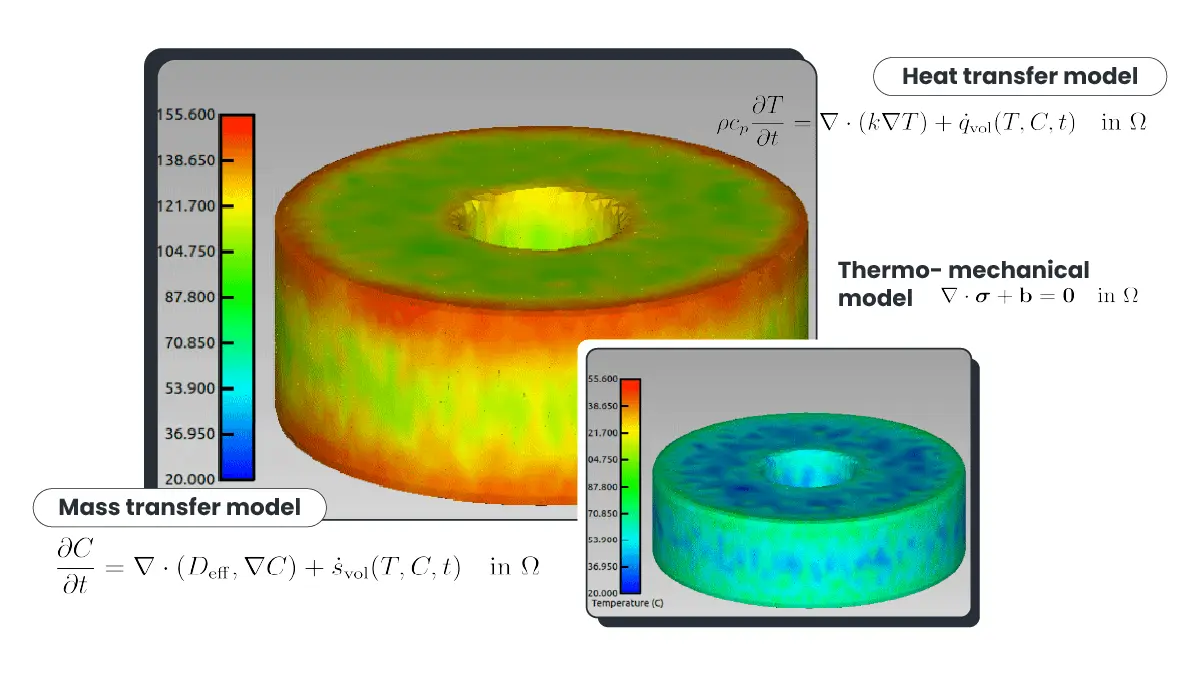
Maps moisture migration and Maillard browning. Ensures uniform structure at scale across oven configurations.
Coupled multiphysics simulation: mass transfer, heat transfer, and thermo-mechanical equilibrium solved simultaneously across the process domain — enabling predictive insight into temperature and moisture distribution.
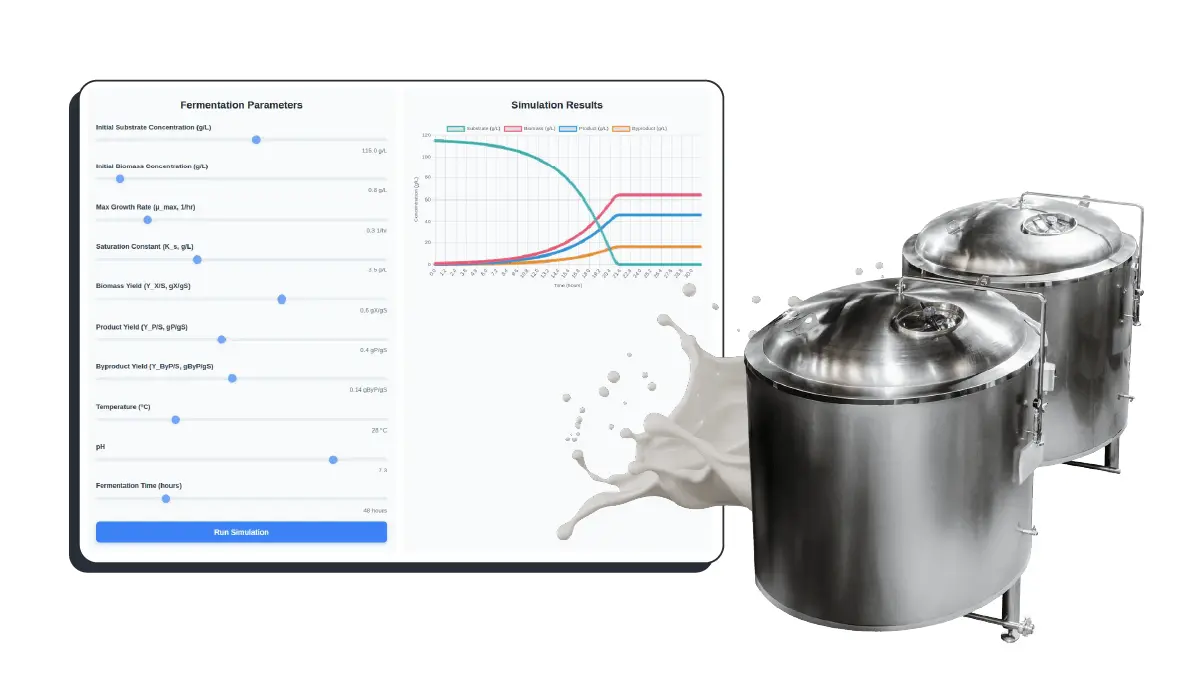
Models biomass growth and metabolite production. Optimizes yield and batch consistency across fermentation conditions.
Dynamic simulation of fermentation kinetics: substrate, biomass, product, and byproduct profiles resolved over time and continuously refined through real process data.

Heat and mass transfer for spray, drum, and belt drying.
Multiphysics treatment of moisture removal across drying modalities, with particular focus on shelf-stable food and supplement powder applications. Contact us to discuss early-access pilots.
PIPA platforms operate today inside some of the most demanding enterprise environments in food and nutrition — clearing the procurement, security, and integration bars that come with global CPG deployments.
Hosted in PIPA's secure cloud, or deployed inside your own infrastructure for the strictest data-residency and IP-isolation requirements. Customer choice, not our preference.
Permission controls at the project, workspace, and dataset level. Integrates with enterprise identity providers for single sign-on and centralized user management.
Connects to your tools, internal material databases. Ingests proprietary recipes, TDS, and production logs in the formats your teams already use.
Every formulation, experiment, and result is stored centrally with full version history. Compare iterations, track changes, roll back, and generate regulatory-ready audit trails.
Customer proprietary data stays isolated. Models can be trained on customer data at customer choice, with full control over what's shared and what stays private.
Deployed across global CPG enterprises — operating through their procurement processes, security reviews, and multi-region requirements.
GDPR-aligned data handling practices. Data Processing Agreements available for customers operating under EU or California privacy regimes. Additional compliance documentation provided as part of enterprise procurement review.
Service Level Agreements tailored to enterprise deployment scope. Audit rights, uptime commitments, and support response times negotiated as part of the Master Services Agreement.